架設自己的 AI 語言模型實驗室不求人之 LM Studio

前言
相信大家已經被 AI、ChatGPT 等各種大型語言模型轟炸了好一段時間,然後也都是使用 ChatGPT、Claude.AI 這種 Web 服務,這些服務的好處是可以快速上手、使用方便,但缺點就是需要網路連線、資料隱私問題、API 費用等等,那有沒有辦法可以本地自行架設 AI 呢?答案是有的,所以這一篇將會來介紹一個很方便使用的工具,它就叫做 LM Studio。
什麼是 LM Studio
LM Studio 是一款專門可以讓你輕鬆在本地使用 LLM(大型語言模型)的工具,這個工具的特色是可以讓你在本地使用各種不同的 LLM 模型,並且可以很方便的進行模型的調整、測試等等,這樣就不需要再依賴網路上的服務了。
雖然整體介面都是英文的,但是其實操作起來很簡單,所以只需要懂一些基本概念,就算是小白也可以在本地起一個屬於自己的 Chat Bot。
Note
本篇文章將會用 Mac 作爲示範環境,Windows 的介面基本上大同小異。
安裝 LM Studio
安裝的方式很簡單,你只需要到 LM Studio 的官方網站就可以下載相關的版本了。
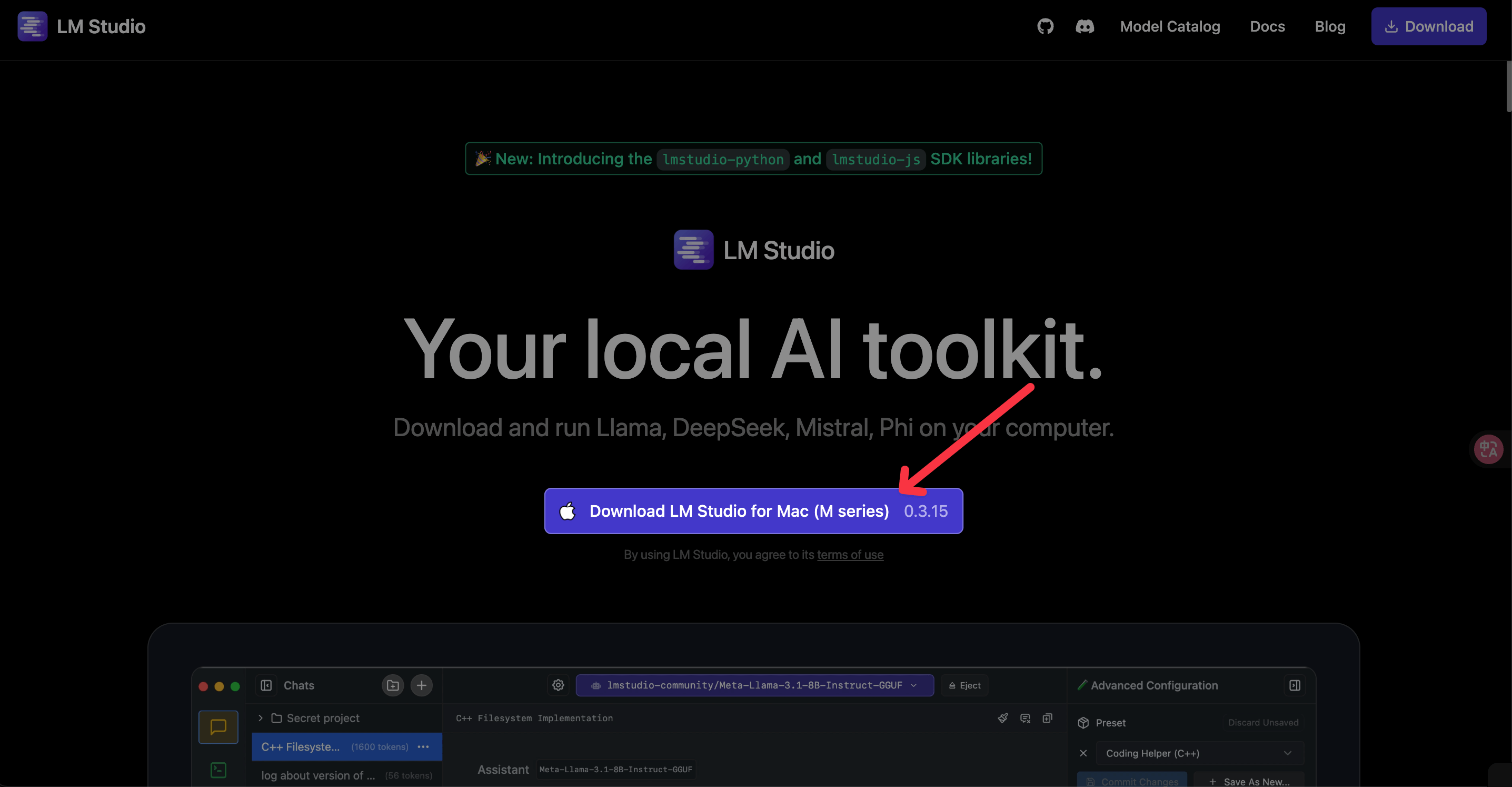
安裝過程我就不多介紹了,因為非常簡單,就只是單純的點擊安裝而已。
使用 LM Studio
初次打開 LM Studio 的時候,基本上你會看到以下畫面:
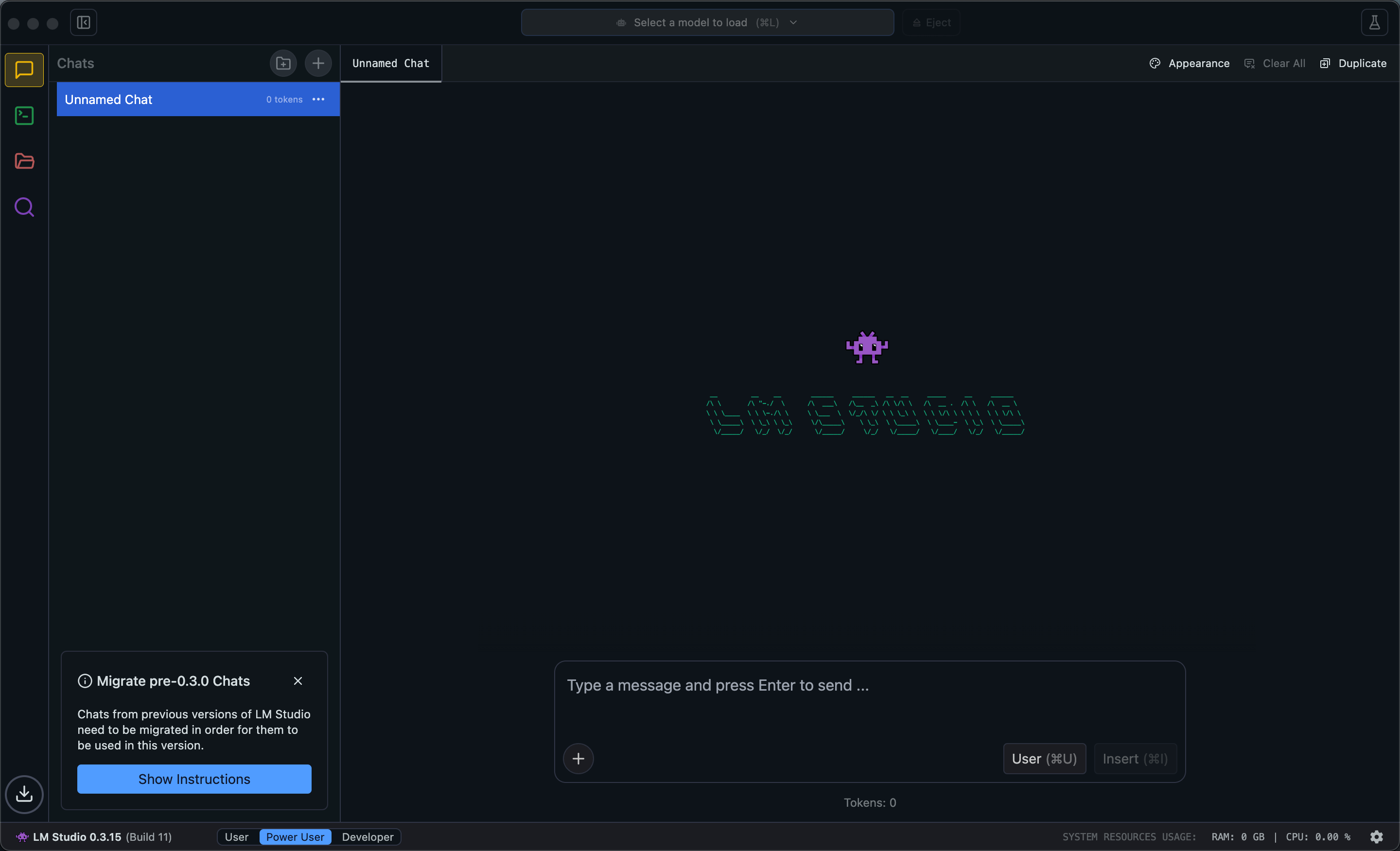
初次看到不用太擔心,這邊我會附上中文翻譯讓你比較好理解,這邊讓我們先從左側邊欄開始介紹:

- Chat:讓你跟 AI 聊天的地方,簡單來講就是 ChatGPT 的地方。
- Developer:這邊稍微比較進階一點,就是讓你可以針對你選擇的模型轉換成 API 的地方,這邊可以讓你使用 Python、Node.js、Go 等等的語言來進行開發。
- My Models:就是你下載的模型放置處
- Discover:簡單來講,就是發現/探索模型的地方,你可以在這邊下載各種不同的模型,這邊會有一些推薦的模型,還有一些熱門的模型等等。
- Downloads:顯示你下載的模型的進度,還有一些下載的紀錄等等。
準備下載模型
如果你沒有把這一篇看完,就急著接過去 Chat 跟機器人聊天的話,基本上你會收到這個錯誤訊息:
1 | |
因為我們還沒有下載任何一款大型語言模型。
所以這邊要請你點一下 Discover 的圖示,這時候會跳出一個視窗
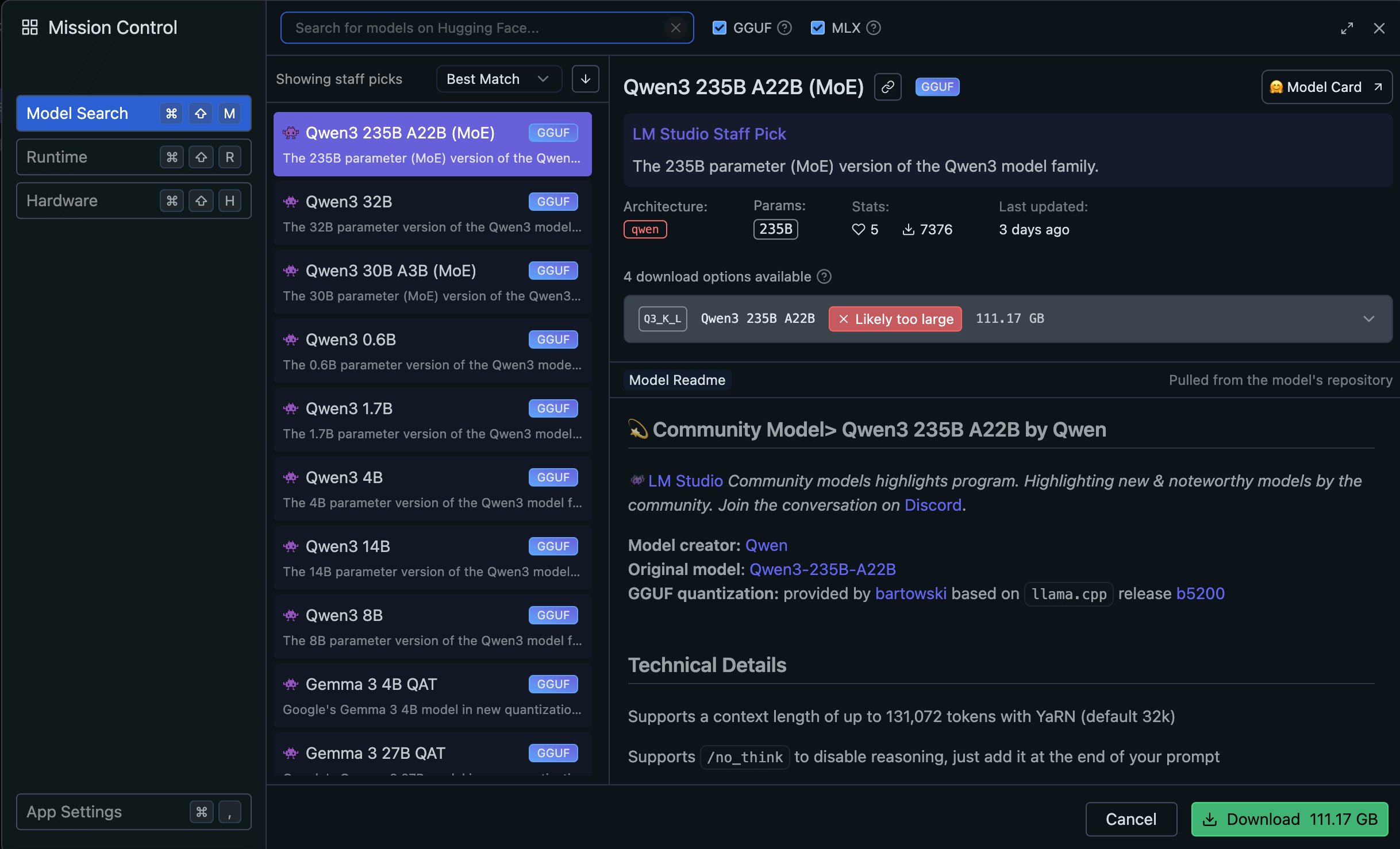
再開始下載之前,我們要先認識幾個東西,也就是模型參數。
模型參數?
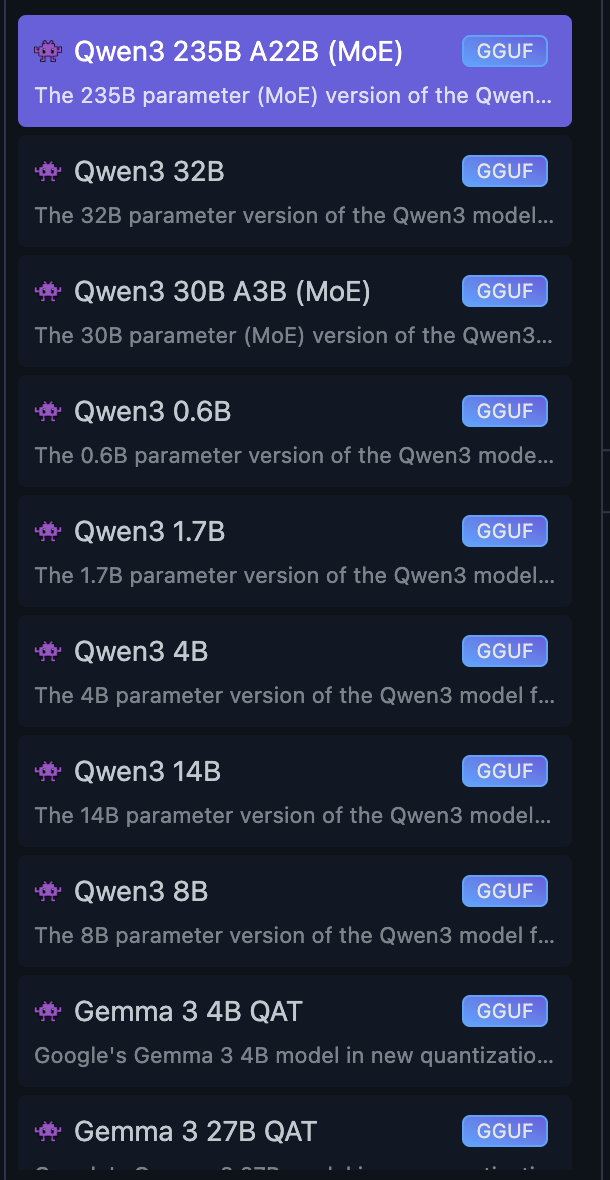
在模型列表上,我們可以看到每個模型後面都有個神秘的英文字母+數字,這邊我隨便挑幾個來解釋一下:
- Qwen3 235B A22B(MoE)
- Qwen3 4B
- Gemma 34B QAT
- DeepSeek R1 Distill (Qwen 7B)
- Llama 3.3 70B Instruct
首先,以 Qwen3 4B 來講,Qwen3 是模型的名稱,4B 是參數的大小,也就是這個模型有 40 億個參數,參數量越多也代表著模型可以學習到的資訊越多,這個模型的表現也會越好。
而常見的代號有:
B:表示 Billion(十億),例如 4B 就是 40 億個參數。M:表示 Million(百萬),例如 4M 就是 400 萬個參數。T:表示 Trillion(兆),例如 4T 就是 4000 億個參數。
那…MoE 跟 QAT 這些又是什麼呢?
MoE:Mixture of Experts,簡單來講,你可以想像成這個模型邀請了不少專家來幫忙,這樣可以讓模型在某些特定的任務上表現得更好,但這樣的模型通常會比較大,因為它需要儲存更多的專家模型。QAT:Quantization Aware Training,這種類型模型在一開始設計與規劃時,就會把它壓縮的比較小,這樣佔用記憶體以及邏輯推理上也會比較快,但也不會失準太多。Instruct:這個模型已經有經過微調(Fine-Tuning)過,通常是針對某些特定的任務進行微調,這樣可以讓模型在這些任務上表現得更好。Distill:簡單來講,這個模型已經精簡(Distillation)過,通常這種都是經過較大的模型,然後萃取出精華的部分,所以會比較小也比較快,但缺點就有可能少一些知識等。
所以這邊我們看到 Qwen3 4B 的時候,就可以知道這麼模型叫做 Qwen3,參數量是 40 億個,這個模型沒有 MoE、QAT、Instruct、Distill 等等的標記,所以這個模型就是一個原始的模型。
但裡面有一個很特別的名稱,也就是 Qwen3 235B A22B(MoE) 這個代表著,它雖然有 2350 億個參數,並且是多位專家一起合作的模型,只是實際上運作只會使用 22B 的參數量,因為它想要節省資源哩,更白話一點解釋就是,雖然我們有 2350 億本書,但是每次只會借 22 本書來看,不用每次都翻閱 2350 億本書,藉此來節省資源,所以這個 A22B 就是代表著這個模型的運作參數量(Active 22B)。
還需要注意什麼?
下載模型之前,也都會建議你要點一下 Model Card,這邊會有一些模型的介紹、使用建議等等。
這邊舉例來講,我挑選 DeepSeek R1 Distill (Qwen 7B) 這個模型
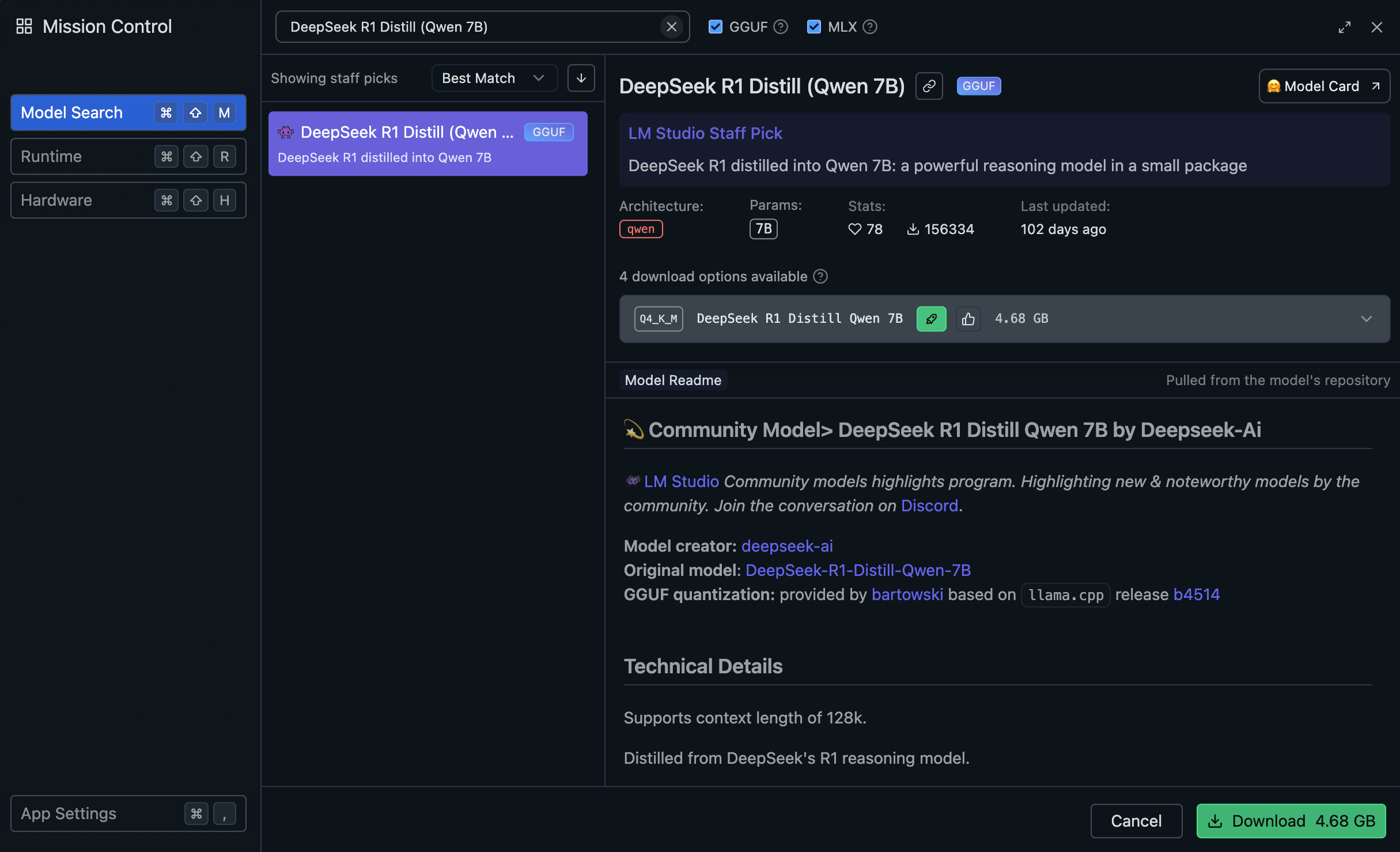
我們可以先看幾個重點:
- DeepSeek R1 Distill (Qwen 7B)
- Q4_K_M DeepSeek R1 Distill Qwen 7B 4.68B
我們可以看到這一組模型很特別,它名稱是 DeepSeek R1 Distill (Qwen 7B),所以該怎麼看呢?
- DeepSeek:模型名稱
- R1:這個模型是 R1 的版本
- Distill:這個模型是經過精簡的模型
- Qwen 7B:這個模型是從 Qwen 7B 的模型精簡過來的
簡單一點來講就是 DeepSeek 跑去跟 Qwen 7B 學習請教,然後把 Qwen 7B 的知識萃取出來精簡成小型版本,所以這個模型會更小更快,但還能保留大部分原本的聰明才智哩!
而 Q4_K_M 這個代表著這個模型的量化方式(Quantization)。
什麼是量化(Quantization)?
你如果嘗試點一下 Q4_K_M,你可以看到更多這種奇妙的數字
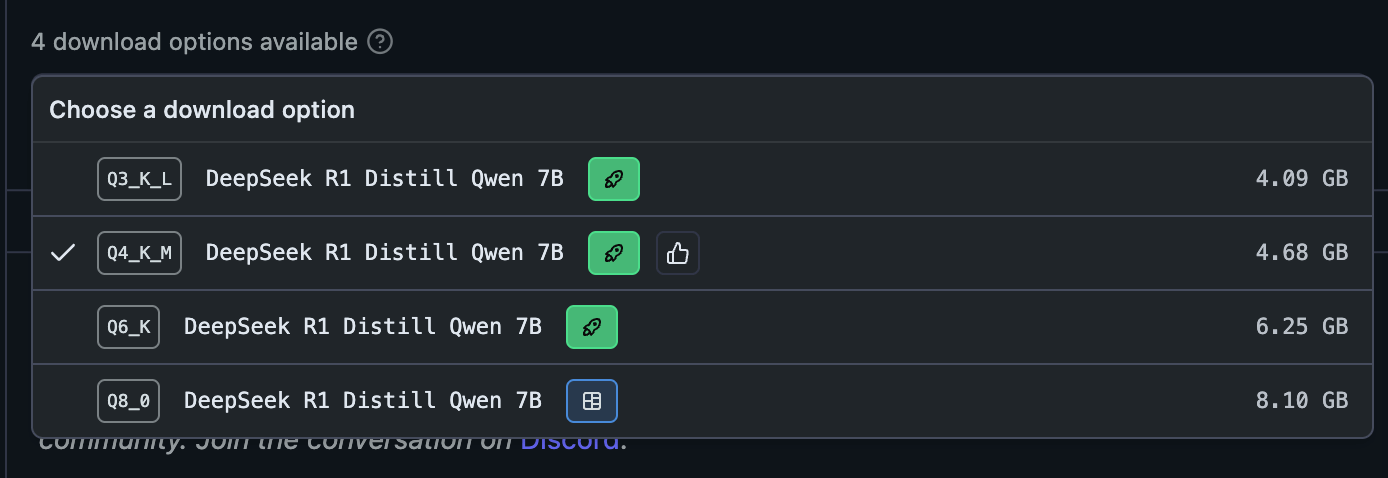
- Q3_K_L
- Q4_K_M
- Q6_K
- Q8_0
那這些奇妙的數字又是什麼意思呢?簡單來講,這些數字就是代表著這個模型的量化方式,以 Q4_K_M 來拆解舉例的話
- Q4:這個模型是 4-bit 的超小版本,通常越小越省記憶體
- K_M:是指這個模型的壓縮方式
- K_L:代表壓縮比較少,保留最多原本模型細節,效果最好
- K_M:壓縮方式適中,速度雖然快但也有不錯的表現(常見推薦版本)
- K_S:壓縮最多的版本,速度是最快的
- K_0:代表接近原始版本,但還是有一點壓縮
- _0:代表使用最基本的量化方式,效果接近原版,但仍然是有進行量化壓縮的。
當然,還有很多細節沒說明,這邊就不一一介紹了,這邊只是讓你知道這些代號的意義,方便你可以快速下載想要的
下載並開始用
前面基本知識熟悉差不多後,我們就可以來正式下載模型了。
這邊請你在 Search 的地方輸入 DeepSeek R1 Distill (Qwen 7B),接著選擇 Q4_K_M 這個版本,然後點擊 Download 按鈕
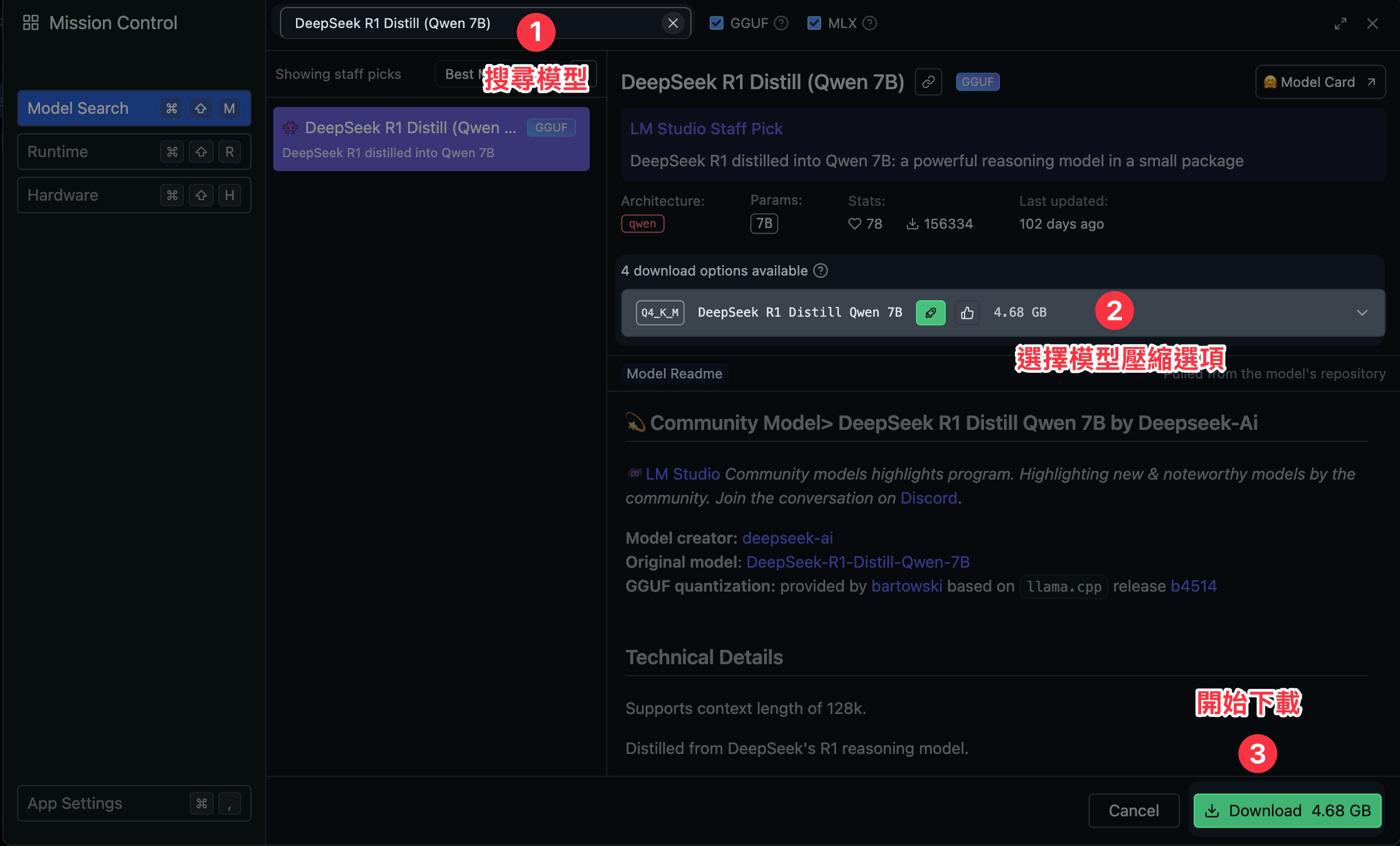
接著就等這個模型下載完畢吧~
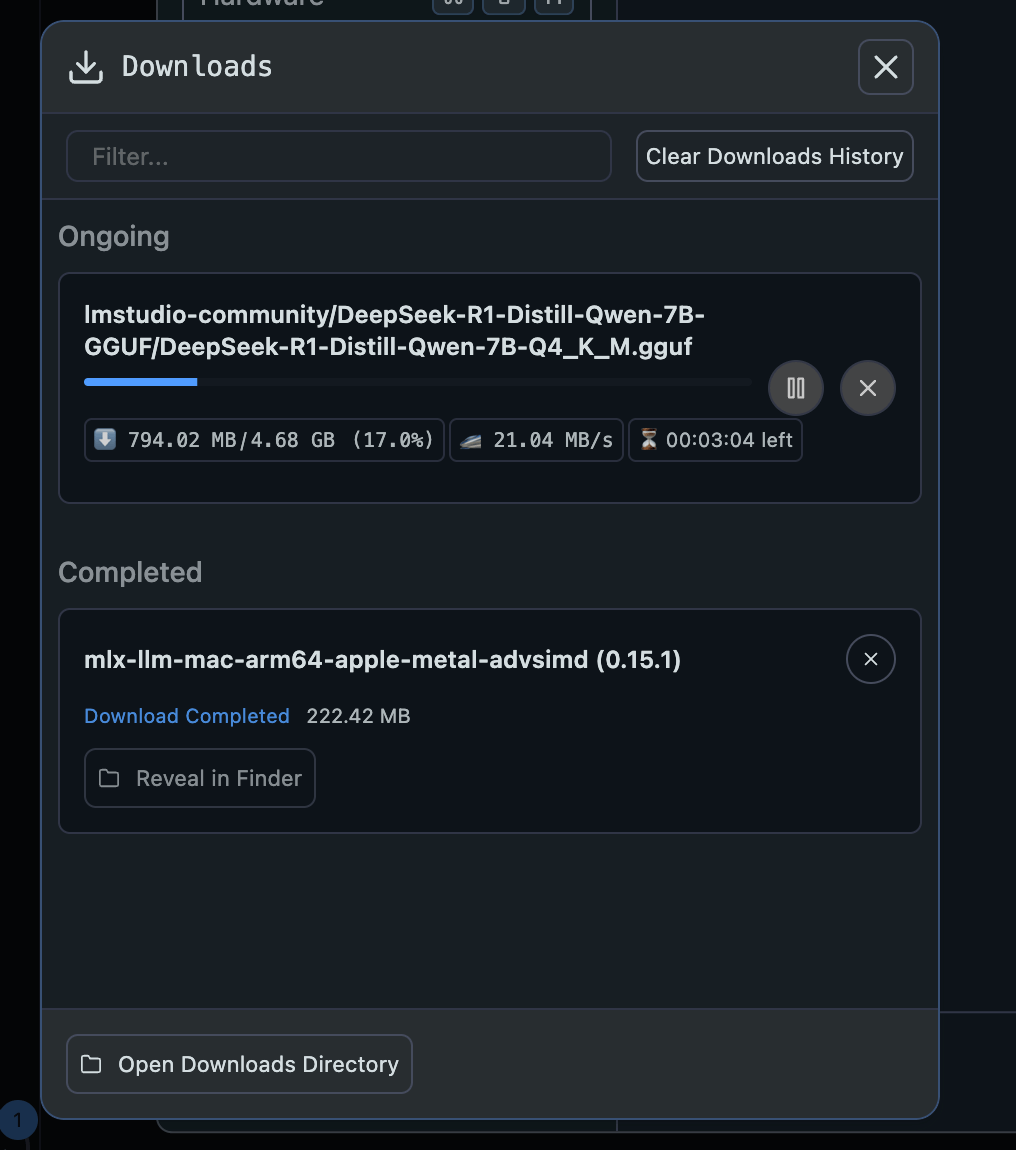
下載完畢後,你就可以點一下 Load Model

點下去後,你就會跳到 Chat 頁面,然後上面可以看到 Model 正在載入中(上方讀取條)
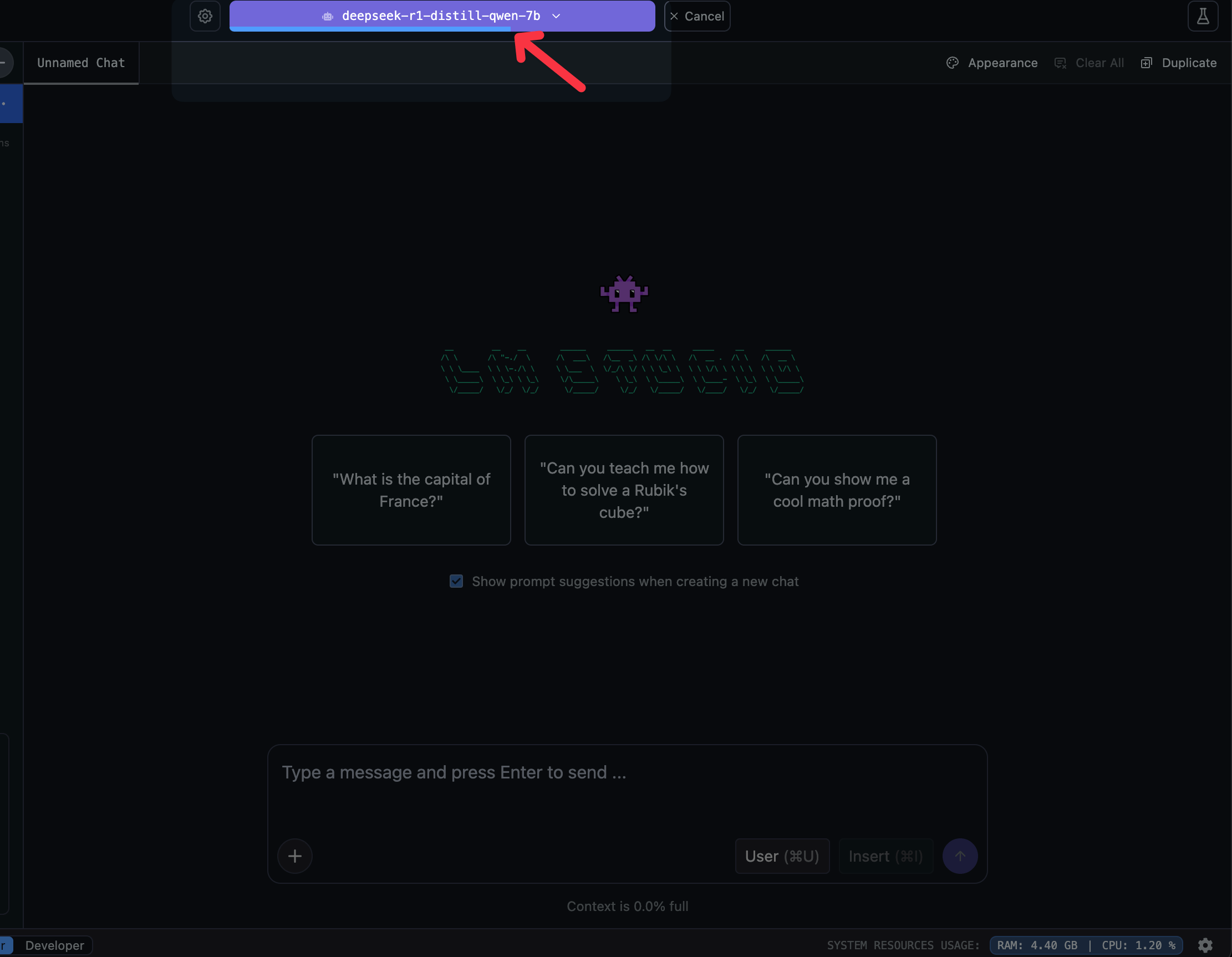
跑完之後,你就可以對話啦~
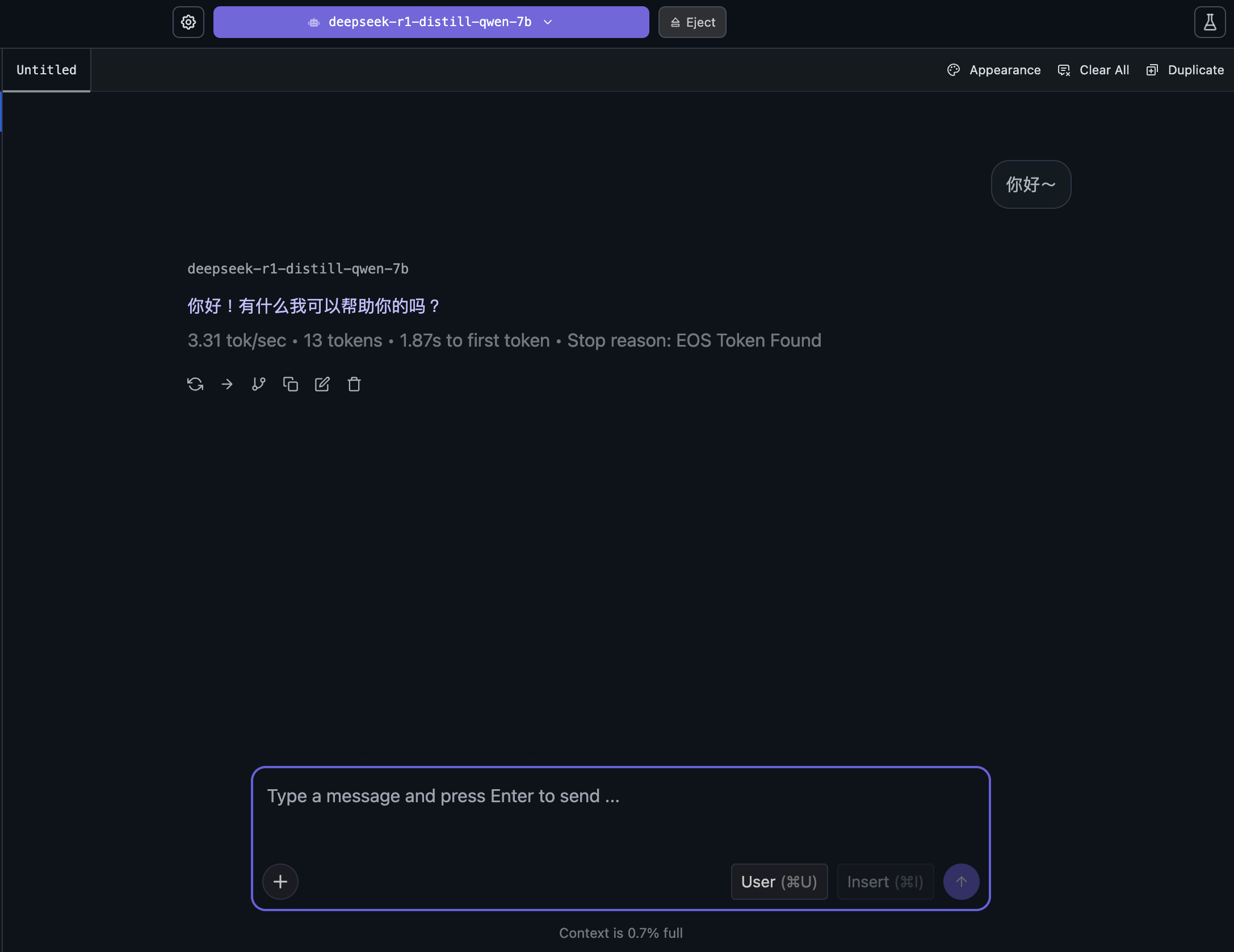
那該如何退出或終止模型呢?很簡單,你只要點一下上方 Eject 就可以啦~

想要重新掛載回去也很簡單,點一下 Select a model to load,就會跳出視窗讓你選擇模型哩
就介紹到這裡囉~
以上就是 LM Studio 的基本使用方式,讓你可以很快速地搭建屬於自己的 AI 聊天機器人哩!
如果我的筆記讓你少踩一個坑、節省 Debug 的時間,
也許你可以請我喝杯咖啡,讓我繼續當個不是 Array 的 Ray ☕
 |
|
 |
|