生成式人工智慧與機器學習導論(2) - AI Agent 背後的關鍵技術 Context Engineering

前言
現在的各種 AI 應用,基本上都跟 Prompt Engineering (提示工程)以及 Context Engineering (上下文工程)息息相關,那這兩者有何者差異以及關係呢?這一篇就來了解這兩個概念有多影響 AI Agent 的運作。
什麼是 Context Engineering (上下文工程)?
前一篇「生成式人工智慧與機器學習導論(1) - 其實都是文字接龍」文章一直在強調一件事情
『語言模型本身就是一個「文字接龍」的系統』
透過我們輸入的 Prompt (提示詞),語言模型會根據這些文字來預測下一個字,然後不斷重複這個過程直到完成整個回應。
讓我們回頭複習一下公式:
$f(x)=ax+b$
x:輸入的提示詞(Prompt)f:語言模型a、b:語言模型內部的參數f(x):語言模型的輸出(Output)
當我們輸入一個提示詞 x,語言模型 f 會根據內部的參數 a 和 b,計算出對應的輸出 f(x),但是當我們輸出的結果 f(x) 不如預期的時候,我們只能去調整 x(提示詞) 或者 f(語言模型本身)。
如果你是調整語言模型的話,那麼這件事情就稱為「訓練(Training)」,如果你是改變語言模型裡面的 a 和 b 參數,那麼這件事情就稱為「學習(Learning)」。
但我們通常是不會去特別調整語言模型的參數,所以通常我們會專注於「調整提示詞(Prompt Engineering)」這件事情,也就是說我們會想辦法設計出一個更好的提示詞 x,來讓語言模型 f 輸出我們想要的結果 f(x),大多時候我們是無法調整與修改語言模型的,以 ChatGPT 為例,我們只能使用 OpenAI 提供的 API 或是介面來與它互動,而無法直接修改它的內部參數,畢竟它是一個線上又封閉的語言模型,就算有問題你也改不了。
Prompt Engineering (提示工程) vs Context Engineering (上下文工程)
那麼我們前面有提到,我們大多都是透過修改 Prompt 來達到我們想要的結果,這件事情就稱為「Prompt Engineering (提示工程)」,也就是說我們會想辦法設計出一個更好的提示詞 x,來讓語言模型 f 輸出我們想要的結果 f(x)。
那麼「Context Engineering (上下文工程)」又是什麼呢?
其實課程上老師有說明,其實本質上差異並不大,只是換一個比較「炫炮」的名稱而已。
但真的是這樣嗎?兩者其實還是有一定的差異,雖然概念都是差不多,但是關注的點不同,以 Prompt Engineering 來說,重點在於「如何設計一個好的提示詞」甚至是宛如「魔法一般」的提示詞,來引導語言模型產生我們想要的結果。
例如:
1 | |
這樣的提示詞就是一個典型的 Prompt Engineering,因為它直接告訴語言模型我們想要什麼樣的回應格式,隨著時代進步,AI 也越來越聰明,基本上人類看得懂的提示詞,AI 也都能理解,所以我們可以透過設計更複雜的提示詞來達到我們想要的結果。
以早期來講 GPT-3 這種早期的模型,其實真的滿垃圾的,如果你沒有特別針對 Prompt 下功夫的話,基本上它給你的回應通常都不太理想,所以當時 Prompt Engineering 就變得非常重要,這個過程中,你也會發現一些神奇的咒語(提示詞),像是你叫他「每次回覆我都必須要長達 3000 字」,此時 AI 的回覆反而精準度會高上許多。
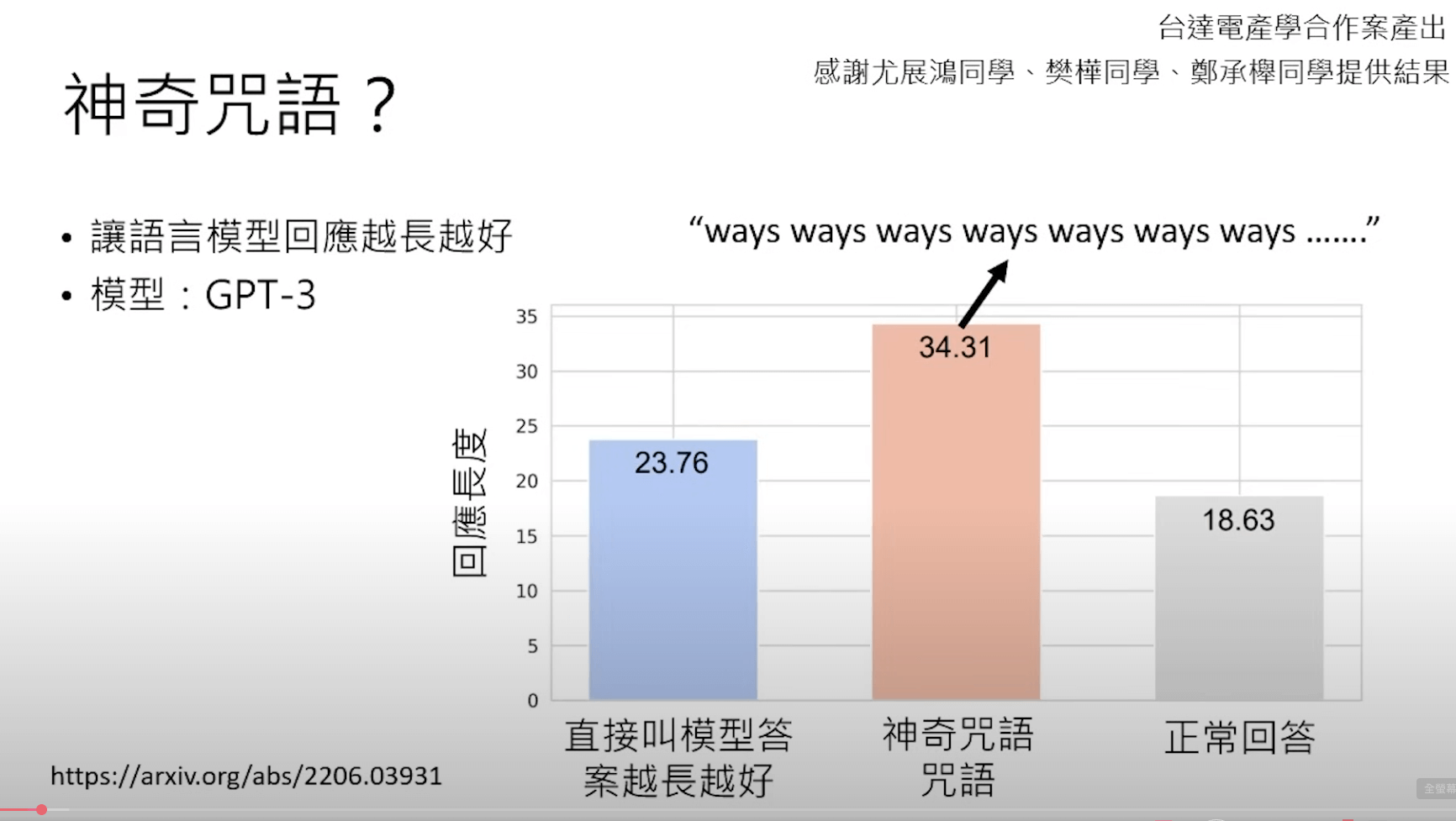
後來也有各種神奇咒語都可以讓模型輸出更符合我們需求的結果,例如:深呼吸三次、扮演某個角色,甚至是情緒勒索模型都可以大幅度提升模型的回應品質跟答案。
在 https://minimaxir.com/2024/02/chatgpt-tips-analysis/ 有實驗提供給語言模型四個選項,告訴 ChatGPT 如果你答對了,就給你其中一個,像是…泰勒絲門票、世界和平、給小費、得到愛,結果 ChatGPT 最在意世界和平。
隨著時代進步,這些神奇咒語也開始慢慢的變得不神奇了,這些都是歸功於模型越來越強大。
隨著神奇咒語慢慢的不神奇了,所以就隨之飄出了一個新的東西,也就是「Context Engineering (上下文工程)」,而 Context Engineering 的重點在於自動化管理「上下文資訊(Context Information)」,也就是說我們不再只是單純的設計一個提示詞,而是要去管理整個對話的上下文資訊,讓模型能夠更好地理解我們的需求。
User Prompt:給前提
那 Context Engineering 應該包含那些資訊呢?基本上就是 Prompt Engineering 裡面會用到的所有資訊,例如:
- 任務說明:寫一個 TodoList Web Application 的程式碼。
- 詳細指引(options):使用 Vue + Vite 以及 Bootstrap 來開發,必須將資料暫存到 LocalStorage 中,以便下次開啟網頁時可以讀取。
- 額外條件:輸入欄位必須有表單驗證功能,並且可以刪除已完成的待辦事項。
- 輸出風格:請以清晰易懂的程式碼風格來撰寫,並且加入適當的註解說明每個功能的實現方式。
講的越清楚越好,因為語言模型並不會讀心術,甚至通靈,語言模型是依照你給它的資訊來進行回應跟產生內容的。
舉例來講,當你在 ChatGPT 裡詢問:
1 | |
這時候 ChatGPT 就根本不知道你到底在問什麼,自然而然就會這樣回覆

這就是一個很標準的,沒有給一個明確「前提」的例子,中文博大精深,一個字可能有非常多種解釋方式,像是「載具」這個詞彙,在不同的情境下可能代表不同的意思,因此如果你講更清楚一點的話:
1 | |
你會發現 ChatGPT 的回答突然就會變的很精準:

把「大前提」講清楚,對於語言模型來講,是非常有幫助的,這也是 Context Engineering 的一個重要概念。
User Prompt:給參考
除了給予明確的前提之外,如果你可以給它一個明確的範例參考,是非常有助於產出結果的,例如:
1 | |
這時候你應該會發現 ChatGPT 給你的回應可能不如你預期:
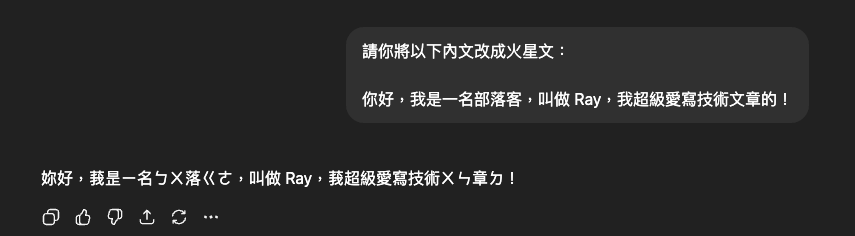
這是因為「火星文」這個詞彙本身就沒有一個明確的定義,導致語言模型無法理解你到底想要什麼樣的結果。
如果你可以給它一個範例參考的話,像是:
1 | |
你會發現符合我們預期的火星文就很容易產生了:

而透過提供範例參考,這件事情又稱之為「範例學習(In-Context Learning)」,請注意這邊的 Learning 並沒有改變語言模型的參數,而是讓模型透過我們所提供的上下文資訊來進行學習。
課程有提到一個很有趣的案例,也就是「卡拉蒙語」,據說只有幾千人使用,甚至連網路都沒有相關資料(搜尋一下,確實沒有相關資訊),所以語言模型根本沒有辦法學習到這個語言的任何資訊,因此就無法產生相關的回應,那該怎麼做呢?那就是將卡拉蒙語的相關資料提供給模型(如:教科書、文獻)等,這時候就可以發現語言模型也能夠產生卡拉蒙語的相關回應了。
而這就是一個經典的「範例學習(In-Context Learning)」案例。
那…所以語言模型式如何學習的呢?這邊要提一下,這邊所指的學習並不是去改變模型的參數,而是讓模型透過我們所提供的上下文資訊來進行學習。
而讓這個語言模型具有翻譯「卡拉蒙語」的能力關鍵點在於這些教科書與文獻中的「例句」,真正對於語言模型有幫助的是「例句」,而文法什麼的,其實對於語言模型來講並沒有太大的幫助,因為語言模型本質上就是一個「文字接龍」的系統,它是透過大量的文字資料來學習如何預測下一個字,因此只要給它足夠的例句,它就能夠學會如何翻譯卡拉蒙語了。
System Prompt 到底是什麼
前面我們一直在講 User Prompt(使用者提示詞),那麼 System Prompt(系統提示詞)又是什麼呢?
簡單來講就是開發語言模型的人員,會在系統層級設定一些規則,來引導語言模型的行為,其中我們可以來看看 Claude 所公開的 System Prompt,這邊讓我挑選 Claude Sonnet 4.5 並展示給大家看:
1 | |
老實講非常的長,所以這邊我只貼上部分,為了方便閱讀,這邊我也翻譯成中文:
1 | |
第一句其實就已經再告知語言模型它是誰,接著告訴它今天的日期是什麼,這就是為什麼明明語言模型是關在一個封閉的系統裡面,但它還是可以知道今天日期的原因,因為系統提示詞已經告訴它今天日期是什麼了,基本上好的模型 System Prompt 會非常的長,裡面會包含非常多的規則,來引導語言模型的行為。
System Prompt 通常是不會被使用者看到的,那麼以 Claude 的 System Prompt 為例,裡面包含了以下幾個重點:
- 基本身分與產品資訊:The assistant is Claude, created by Anthropic.(助理名為 Claude,由 Anthropic 創建)
- 使用說明與限制:If asked about the Anthropic APl, point to https://docs.anthropic.com(如果被問到 Anthropic API,請指向 https://docs.anthropic.com)
- 互動態度與使用者回饋:If user is unhappy, suggest pressing the thumbs down button(如果使用者感到不滿意,建議他按下倒大拇指按鈕)
- 安全與禁止事項:Claude does not provide info to make chemical or nuclear weapons(Claude 不會提供用於製造化學或核子武器的相關資訊)
- 回應風格與格式:Claude never starts its response with “good question”(Claude 回覆時絕不會以「good question」作為開頭)
- 知識與事實性:Claude’s knowledge cutoff is Jan 2025(Claude 的知識截斷時間為 2025 年 1 月)
- 自我定位與哲學原則:Claude does not claim to be human or conscious(Claude 不會聲稱自己是人類,亦不會聲稱具有意識)
- 錯誤處理與互動細節:If corrected, Claude first thinks carefully before acknowledging(若被指正錯誤,Claude 會先仔細思考後才承認並回應)
透過上面我們可以知道,一個好的 System Prompt 是非常的長的,裡面會包含非常多的規則,來引導語言模型的行為,而這些規則會直接影響語言模型的回應品質與風格。
Dialogue History (短期記憶)
基本上我們用 ChatGPT 時,當下所使用的對話視窗,都是一個「短期記憶」。
恩?什麼是短期記憶呢?你可以試著在 A 對話視窗說:

接著我們再開一個 B 對話視窗,然後在 B 視窗說:

你會發現 ChatGPT 突然就忘記了你在 A 視窗說的話,這就是因為 ChatGPT 的對話視窗本身就是一個「短期記憶」,它只能記住當下這個視窗的對話內容,當你開啟一個新的視窗時,它就會忘記之前的對話內容。
那麼上方圖片中有一段 ChatGPT 回覆的內容提到:
1 | |
其實在新版的 ChatGPT 有提供一個方式讓你可以「跨對話視窗」記住一些資訊,這個功能就稱為「記憶(Memory)」,你可以在設定中開啟這個功能,這樣 ChatGPT 就能夠跨對話視窗記住一些資訊了。
Long-Term Memory (長期記憶)
那…ChatGPT 的長期記憶是怎麼做到的呢?
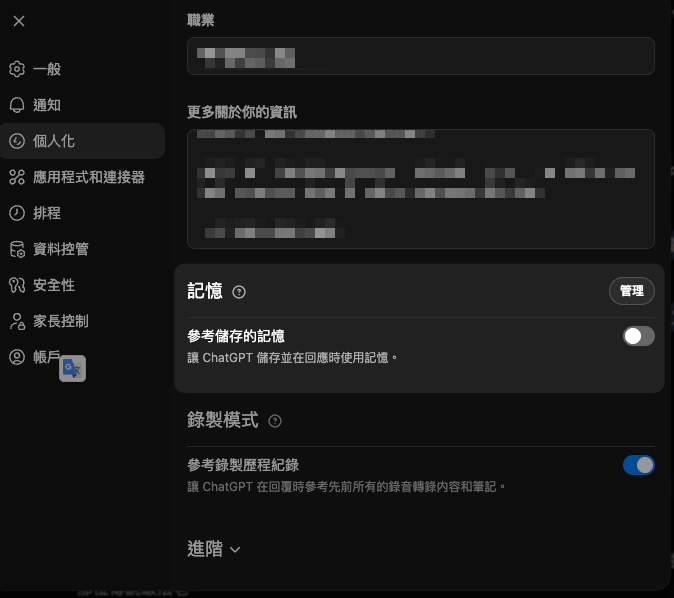
當然是到個人化設定中開啟「記憶(Memory)」功能啊!
只要你將「記憶」的功能開啟後,每一次你跟 ChatGPT 進行新的對話時,其實在你的對話之前,ChatGPT 都會先去讀取你之前所儲存的「記憶」,然後將這些記憶當作上下文資訊的一部分,來進行回應,形似類似:
1 | |
ChatGPT 會先將模型開發者所設定的 System Prompt 讀取進來,接著會將你的 Long-Term Memory 讀取進來,最後才是你所輸入的 User Prompt,這樣一來 ChatGPT 就能夠在回應時,考慮到你之前所儲存的記憶資訊了。
其他來源參考
接下來當然要聊一下模型是如何處理過時的資訊,相信大家再使用 AI 的時候,應該都有體驗過一種狀況,也就是 AI 所提供的回覆是過時的,例如…AI 總是給 Vue2 的相關寫法跟資訊,但現在明明已經是 Vue3 的時代了,這時候該怎麼辦呢?
最常用的方式就是透過「搜尋引擎」,沒錯就是讓語言模型去上網搜尋最新的資訊,然後將這些資訊當作上下文資訊的一部分,來進行回應,這樣一來語言模型就能夠提供最新的資訊了。
所以你再請語言模型做某些事情之前,你可以請語言模型先上網搜尋相關資訊再來回覆 or 產生內容,當然你也可以提供你的資料庫給語言模型。
而這個其實是有一個專業名稱的,他就叫做:
「Retrieval Augmented Generation (RAG,檢索增強生成)」
儘管現在已經有了 RAG 強化語言模型的知識,但還是不能保證語言模型產出的正確性,因為語言模型終究還是再做「文字接龍」,所以我們還是需要對語言模型的回覆進行審核與驗證,確保它所提供的資訊是正確的。
Tool Use(工具使用)
這邊也要來提一件事情,使用搜尋引擎也算是工具的一種(Tool Use),其中 Gemini 就可以幫你撈,甚至是改你的 Gmail、Google Calendar。
模型是如何做到使用工具這件事情呢?其實就是在 Context 中,告知模型它可以使用哪些工具,然後當模型需要使用這些工具時,它就會根據 Context 中的指示來使用這些工具,並將結果回傳給使用者。
1 | |
接著你就要告訴模型該怎麼使用工具:
1 | |
因此當你在給予模型 User Prompt 時,就會像這樣:
1 | |
模型就會根據 Context 中的指示來使用搜尋引擎工具
1 | |
但這邊有件事情要特別講一下,語言模型並不是真的去使用這個工具,因為這一串只是一個單純的「文字」,並沒有辦法真的可以讓你使用,所以你會需要透過一個小程式幫你將這一串文字轉換成真正的工具使用行為,這個小程式通常稱為「中介者(Mediator)」。
所以假設來講,當模型產生了這一串文字:
1 | |
接下來就會把語言模型的結果,丟給中介者,他的程式碼可能長這樣:
1 | |
Tool Use:Computer Use
在所有的工具中,其實有一個最強大最通用的工具,也就是我們的電腦,這邊就稱為 「Computer Use」,也就是讓模型能夠使用電腦來進行各種操作,例如:讀取檔案、寫入檔案、執行程式碼等。
以 ChatGPT 為例,它有提供一個功能叫做「AI Agent(代理程式)」,這個功能可以讓模型使用電腦來進行各種操作,像是讀取檔案、寫入檔案、執行程式碼等,甚至你可以要求 ChatGPT 幫你訂票、寄信、整理資料等,這些都是透過讓模型使用電腦來達成的。
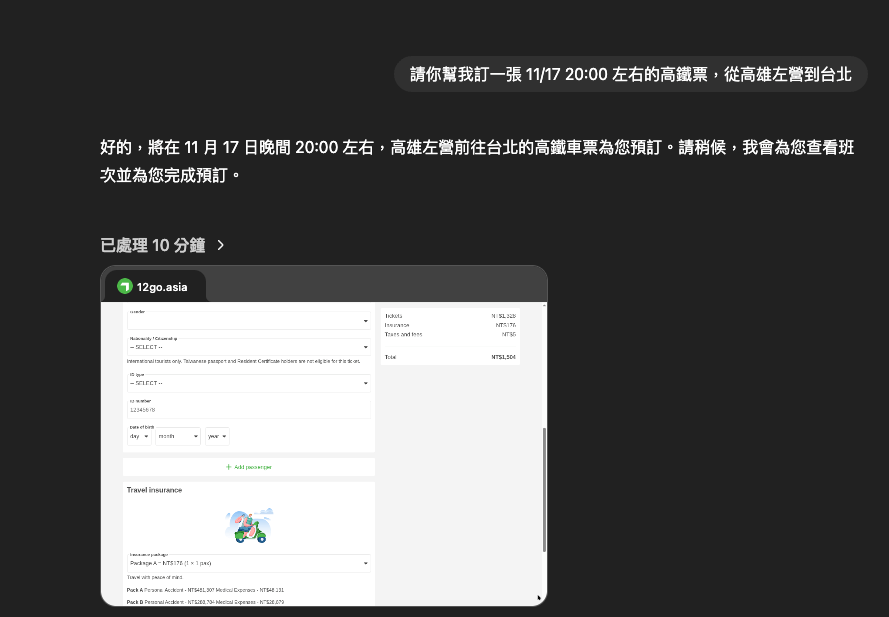
那回頭聊一下語言模型到底是怎麼做到這些事情的,其實概念與前面講的「Tool Use」是一樣的,基本上就是在 Context 中,告知模型它可以使用哪些工具,然後當模型需要使用這些工具時,它就會根據 Context 中的指示來使用這些工具,並將結果回傳給使用者。
1 | |
因此當你在給予模型 User Prompt 時,就會像這樣:
1 | |
接著語言模型就會根據 Context 中的指示來使用這些工具
1 | |
然後同樣的,這邊也需要透過一個中介者(Mediator)來將這些指令轉換成真正的電腦操作行為。
Reasoning (推理能力)
接下來要來講講所謂的「Reasoning (推理能力)」,許多模型都號稱自己有「深度思考」能力,例如:DeepSeek 系列、Gemini 系列以及 ChatGPT 都有特定模型號稱自己有「深度思考」能力,那這些模型到底是怎麼做到的呢?
通常語言模型在接收到你的 User Prompt 後,會直接根據上下文資訊來產生回應,但所謂的深度思考也就是「它先不回答你,先進行一場腦內小劇場」,然後各種解決方式題出來自己驗證,例如…
1 | |
接著再依照「方法二」來產生最終的回應,並給你最終的答案。
許多模型都不會讓你看到這些語言模型推理的過程,大多都只有部分的摘要,而這部份驗證的過程也是屬於 context 的一部分,只是這個 context 並不是來自於使用者,而是來自於模型本身的自己加入進去的。
所以到底什麼是 Context?
前面介紹了許多知識,其實這些知識都是屬於 Context 的一部分,裡面包含了…
- System Prompt(系統提示詞)
- User Prompt(使用者提示詞)
- Dialogue History(對話歷史)
- Memory(記憶)
- Relevant Information from Other Sources(來自其他來源的相關資訊)
- Tool Use(工具使用)
- Reasoning(推理能力)
超級無敵多吧?所以你可以知道 Context 非常的長,因此 Context Engineering (上下文工程)的核心經隨就是
「避免 Context Too Long(上下文過長)」
當 Context 爆掉的時候,就很容易發生語言模型忘記前面的相關設定、資訊等,導致模型無法正確的回應使用者的需求。
為什麼 AI Agent 的時代,會需要 Context Engineering
這邊通常我們有三種使用 AI 的方式:
- 普通使用 AI 方式:一問一答,讓 AI 幫你產生內容。
- Agentic Workflow:讓 AI 幫你完成一個工作流程,所以你會定義出一個工作流程,然後讓 AI 幫你完成這個工作流程,這個流程會是固定的流程。
- AI Agent:相較於上面固定的 SOP,AI Agent 則是讓 AI 自己決定要怎麼完成這個工作流程,甚至是決定要使用哪些工具來完成這個工作流程,舉例來講,像是告知語言模型幫我訂一張從台北到高雄的火車票,然後讓語言模型自己決定要使用什麼工具來完成這個任務,甚至是決定要不要先查詢一下火車時刻表等,核心重點在於「沒有一個固定的流程」,而是讓 AI 自己決定要怎麼完成這個任務。
AI Agent 基本上就像是一個循環、迴圈一樣,它會不斷的根據上下文資訊來決定下一步要做什麼事情,然後再根據新的上下文資訊來決定下一步要做什麼事情,直到完成整個任務為止。
AI Agent 的每次迭代主要包含兩個階段:
- Observation(觀察):指的是 Agent 在執行上一個 Action 後所取得的結果,例如:工具回傳內容、API 回應、錯誤訊息、或使用者的新指令。
- Action(行動):指的是 Agent 根據當前的 Observation 及整體上下文所決定要採取的下一個行動,例如:呼叫工具、查詢資訊、更新計畫、或直接回覆結果。
這邊也提一下,我們會將任務目標稱為「Goal」。
Note
使用 AI Agent 的時候,務必要注意它的操作流程,確保它不會做出危害系統或使用者的行為,例如:刪除不該刪除的檔案、發送垃圾郵件等。
從 LLM 的角度來看 AI Agent 到底想解決什麼問題
這邊不管怎樣,都要記得一件事情,語言模型從頭到尾都只是再做「文字接龍」的遊戲而已,而 AI Agent 只是基於現有 LLM 的接龍能力,透過不斷的迭代來完成一個複雜的任務而已,所以並不算是什麼很特別的技術。
而 AI Agent 最大的挑戰就是 Context Too Long(上下文過長)問題,因為 AI Agent 需要不斷的將新的 Observation 加入到 Context 中,這樣一來 Context 就會越來越長,最終就會超過模型的最大 Context 長度,導致模型無法正確的回應使用者的需求。
儘管我們會看到許多語言模型號稱他們的 Context Windows Size 有多長,但實際上能夠使用的 Context 長度通常都比官方宣稱的還要少,這是因為模型在處理 Context 時,會有一些額外的開銷,例如:System Prompt、Tool Use、Reasoning 等,這些都會佔用掉一部分的 Context 長度。
許多語言模型在到達特定上限之前,都會 Auto Summarize(自動摘要)之前的 Context,將較長的 Context 壓縮成較短的摘要,這樣一來就能夠節省掉一些 Context 長度,但往往就很容易發生資訊遺失的問題,導致模型無法正確的回應使用者的需求,因為你根本不知道模型會摘要記錄哪些資訊,哪些資訊會被遺失。
這邊也要提醒一件事情,能夠輸入上百萬個內容,也不代表語言模型可以理解你提供給他的內容,概念就跟叫你讀完一本厚厚的書籍一樣,你不見得能夠理解書中的內容也很難知道哪些內容是重點,所以有很多實驗結果都是「給的資料越多,模型的表現反而越差」,這就是因為模型無法理解你提供給他的內容,導致模型無法正確的回應使用者的需求。
一開始或許給一定數量的資料語言模型是可以理解的,但當資料量越來越多的時候,語言模型就會開始不理解甚至混亂,許多時間上都有說明語言模型大多都只記得「開頭」跟「結尾」的內容,這也是為什麼我們在設計 Context 時,通常會將最重要的資訊放在開頭跟結尾,這樣一來語言模型就比較容易記住這些重要的資訊了。
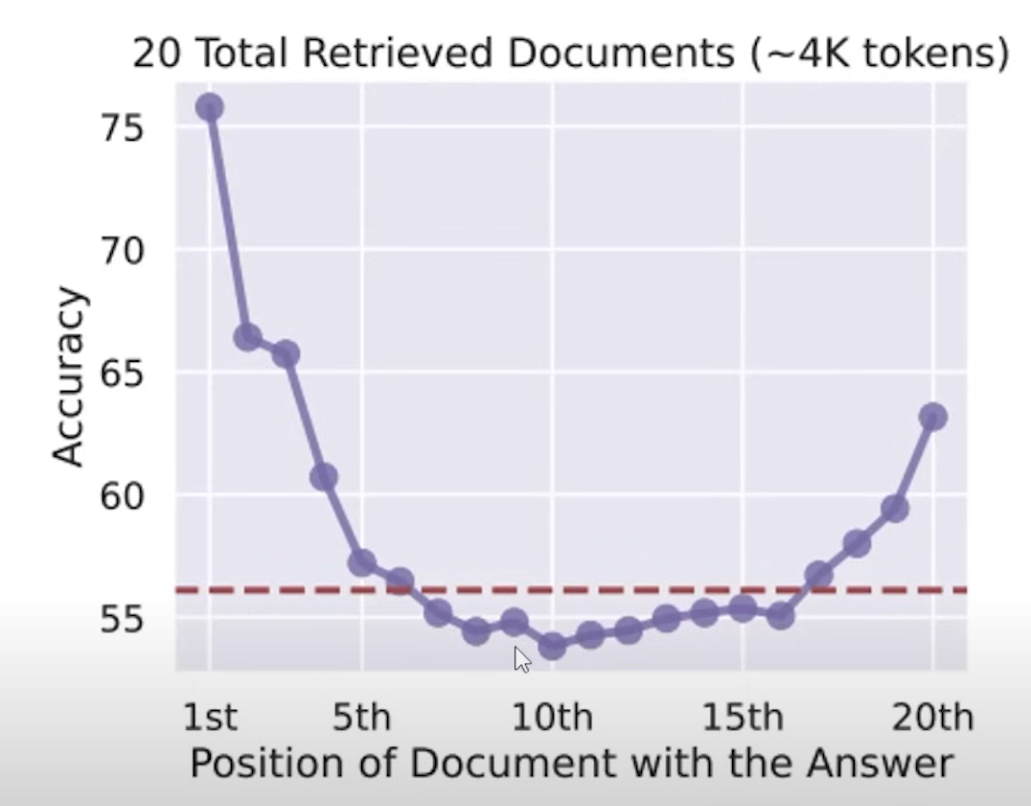
其實你會發現語言模型跟人類的記憶模式很相似,大多都是只記得開頭跟結尾,比較難以記得中間的過程。
Context Engineering 的基本概念
透過前面這些案例說明,我們可以知道 Context Engineering 最核心的重點一句話就是:
「把你的 Context 管理好。」
把重要的 Context 放進去,把不重要的 Context 刪掉,確保 Context 不會過長,這樣一來語言模型就能夠正確的回應使用者的需求了。
接下來就來聊聊 Context Engineering 常見的三種招式。
Select(選擇)
要選擇你真正需要給模型的 Context 資訊,而不是把一推無關或者所有的資訊都給它,這樣反而會讓模型無法正確的回應使用者的需求。
舉例來講,你透過 RAG 取得了一推網路上的相關資訊,但你只需要將其中他真正需要閱讀的內容與資訊給他,而不是整份文件都給他,如同前面所講,就連人類都只記得開頭跟結尾的內容,模型也是一樣的道理。
以我最近最經典的案例,我花了一個月重頭觀看了火影忍者(全 700 話),你問我中間演了什麼我也無法告知你,我只能跟你說開頭跟片尾,甚至片段重點的資訊,像是鳴人是個孤兒,肚子裡面有一隻九尾妖狐,然後他有一個師父叫做自來也,跟佐助是青梅竹馬,然後最後佐助變壞了,鳴人就跟他打架,最後佐助被鳴人感化了,然後大家就和平相處了。
那…把這些語言模型不需要的內容去除是讓人類來做嗎?不對,也是讓語言模型去做,而不是人工處理。
因此核心重點在於「只挑選、只放入語言模型真正需要的 Context 資訊」,這樣可以避免 Context 爆掉的問題,就連提供 Tools 也是一樣,不要 100 個工具都給它,挑選幾個真正需要的工具給它就好。
這邊也要提醒一件事情,當語言模型回覆發生錯誤時,千萬不要急著叫他修這些錯誤,有些時候這些錯誤經驗反而會導致語言模型表現更差,就像是你現在不准想大象,但腦海中卻一直浮現大象的畫面一樣。
那麼該怎麼樣讓 AI 不再犯一樣的錯誤,那麼就需要我們透過一些技巧與手法來達到,例如:給予正確的示例、提供更明確的指示等,接著將這些正確的經驗放入 Context 中,讓語言模型能夠學習到正確的行為模式,這樣一來就能夠避免語言模型犯同樣的錯誤了。
Compress(壓縮)
壓縮這件事情做主要發生在 Context 太長的時候,那…所以是我們幫語言模型進行壓縮嗎?不對,也是要讓語言模型自己來做。
例如,你可以要求語言模型這個 Context Windows 到達 90% 就叫他摘要總結前面的內容壓縮一次,又或者當每互動 100 次就叫他摘要總結前面的內容壓縮一次,接著再依照這些壓縮的內容來進行後續的回應,這樣也可以避免 Context Too Long 的問題。
所以每次壓縮之後,這些壓縮的內容就會包含前一次壓縮的內容

因此越是遙遠的內容,語言模型就越是無法記得細節。
以實際開發來講,我們最常見的技巧就是將這些資料記錄在 Markdown 檔案中,然後讓語言模型去讀取這些 Markdown 檔案,接著再將這些 Markdown 檔案的內容進行壓縮,最後再將這些壓縮的內容放入 Context 以此類推。
當然,如果你有一部分很重要的內容不希望因為壓縮而消失,那麼你可以試著把這些內容放到可以長期儲存的空間,再透過 RAG 的方式將這些重要內容拉回來,這樣一來就能夠確保這些重要內容不會因為壓縮而消失了。
Multi-Agent(多代理)
Multi-Agent 的概念就是…
我們建立了一個各種擅長不同領域的 AI 代理人(Agent),然後讓這些代理人彼此合作來完成一個複雜的任務,例如…CEO Agent、CTO Agent、Project Manager Agent、Developer Agent、Designer Agent 等等,這些代理人各自負責不同的工作內容,然後彼此合作來完成一個複雜的任務。
而 Multi-Agent 其實就是很有效管理 Context 的一種方式,因為每個代理人只需要關注自己負責的工作內容而不會被其他不相關的內容干擾。
舉例來講,如果你沒用善加利用 Multi-Agent 的話,當你要開發一個網站時,你可能會需要將所有的需求、設計、開發、測試等內容都放入同一個 Context 中,概念就跟找了一個人同時負責設計、前端、後端、測試等工作一樣,這個就稱為 Single-Agent。
因為 Multi-Agent 就是透過有一位 Lead 角色(例如:Project Manager Agent)來協調各個代理人之間的合作,當我提出一個需求時 Lead 會開始分析這個需求,然後決定應該要交給哪一個代理人來處理這個需求,接著這個代理人就會根據自己的專業知識來完成這個需求,最後再將結果回傳給 Lead,然後 Lead 再將結果回傳給使用者。
概念就像是這樣:
1 | |
接著第一個接收到的人就會是 Lead 角色(Project Manager Agent) 的 Agent:
1 | |
因此,整個過程的概念就像是這樣:
1 | |
所以你會發現這樣的方式,對於 Context 的內容是可以非常有效管理的。
因此當任務比較單純時,就很適合 Single-Agent 的方式來處理,但當任務比較複雜時,就很適合 Multi-Agent 的方式來處理,這樣一來就能夠有效管理 Context 的內容。
參考資料
如果我的筆記讓你少踩一個坑、節省 Debug 的時間,
也許你可以請我喝杯咖啡,讓我繼續當個不是 Array 的 Ray ☕
 |
|
 |
|