比 MCP 更省 Token 的 Agent Skills - 用 Claude Code 示範

前言
只要你使用過 Claude Code、Gemini、Codex 這些 AI 開發工具的話,那相信你肯定有用過 MCP(Model Context Protocol,模型上下文協定),但本身這些 AI 工具有所謂的 Context 上限,只要使用了 MCP 後,就很容易超出 Context 上限,導致模型無法正常運作,所以這一篇就來聊一下同樣為 Anthropic 所釋出的 Agent Skills,並且用 Claude Code 示範如何使用。
什麼是 Agent Skills?
在深入 Agent Skills 之前,我們得先釐清 MCP 的運作邏輯,否則你怎麼會知道為什麼要用 Agent Skills 呢?
過去我們常遇到 AI 模型「資訊落後」或「看不見私有資料」的問題。MCP 的出現提供了一套標準化協定,讓模型能直接與外部工具(如資料庫、本地檔案、搜尋引擎)串接,即時抓取最新資訊。
然而,MCP 的運作方式本質上是 「資料搬運」 。當你呼叫一個 MCP 工具時,它通常會將抓取到的原始資料(Raw Data)直接塞進對話紀錄中。這會產生兩個主要痛點:
- 大量 Token 稅:大量的 Log、JSON 都會被迅速佔滿模型 Token。
- 雜訊干擾:由於資料太龐大,導致你原本前面下的 Prompt 反而被淹沒,模型無法聚焦在重點上,進而導致「回答」品質低落。
這也是為什麼 MCP 雖然能解決資訊落後的問題,但卻無法有效提升模型的「理解力」與「推理力」。
為了解決這個問題,Anthropic 推出了 Agent Skills。
Agent Skills 的設計理念是 「知識搬運」 ,而非「資料搬運」。
Note
Agent Skills 本質上並不是取代 MCP,而是建立在 MCP 之上,兩者可以互相搭配使用。許多系統還是需要依賴 MCP 來提供給 AI 讀取。
那麼知識搬運跟資料搬運差異在哪呢?簡單來講,就是只給 AI 模型「重點」而非「全部」。這樣的好處可以避免 Token 的浪費以及雜訊的干擾,讓模型能更專注在核心資訊上。
用 Claude Code 示範 Agent Skills
不論是 Gemini 還是 Claude Code 都有支援 Agent Skills 的功能,但這邊會著重於使用 Claude Code 來示範。
首先 Skills 並不是什麼新技術也不是什麼新格式,而是一個單純的 Markdown 檔案,但裡面有一些撰寫規範以及放置方式:
放置方式
首先我們先來聊一下放置方式,Claude Code 有兩種放置方式,分別為:
- 專案類型:
<專案根目錄>/.claude/skills/ - 全域類型:
~/.claude/skills/(macOS/Linux)
這邊要注意,當同名的 Skill 存在於多個位置時,優先順序為:全域 > 專案。也就是說,全域的 Skill 會覆蓋專案的同名 Skill。
Note
優先順序其實還有 Managed 跟 Plugin,如果加入這兩個的話,那麼優先順序就會是 Managed > Personal > Project > Plugin,但普通開發者通常不太會接觸到 Managed 跟 Plugin,所以這邊就不多做說明。
Monorepo 巢狀目錄
如果你的專案是 Monorepo 架構,Claude Code 會尋找巢狀目錄中的 Skills。
舉例來說,當你正在編輯 packages/frontend/src/App.vue 時,Claude Code 除了會搜尋根目錄的 .claude/skills/ 之外,也會自動搜尋 packages/frontend/.claude/skills/ 目錄中的 Skills。
1 | |
這對於 Monorepo 專案非常實用,可以讓各個子專案擁有自己專屬的 Skills,而不會互相干擾。
不論是哪一種放置方式,Skills 都必須放在 .claude/skills/ 資料夾底下,然後有一些規範要注意:
- 每個 Skill 都是一個獨立資料夾(如:
.claude/skills/custom-name-skill/) - 每個 Skill 資料夾裡面至少要有一個
SKILL.md檔案(大寫且固定名稱)
因此標準的結構就會長這樣:
1 | |
而 skill 資料夾裡面可以再放置其他的檔案
1 | |
當然,如果你的結構比較複雜的話,甚至可以拆成多個子資料夾來管理,像是這樣:
1 | |
不論是哪一種結構,核心重點還是在於 SKILL.md 檔案,因為 Claude Code 會讀取這個檔案來了解這個 Skill 的功能與用途。
撰寫規範
那麼接下來講一下 SKILL.md 的撰寫規範,主要是使用 YAML Front Matter 來定義 Skill 的基本資訊,像是這樣:
1 | |
但欄位並不是只有這兩個,底下這邊我也提供完整的欄位說明。
name(必填):必須是小寫字母、數字、連字號,不能有空格或大寫description(必填):最重要的欄位,因為 Claude Code 會用它來決定這個 Skill 適合用在什麼樣的情境。allowed-tools(可選): 限制這個 Skill 執行時可以使用的工具。model(可選):指定執行這個 Skill 時要使用的模型(預設使用對話中的模型)。context(可選):設定這個 Skill 的運作上下文。agent(可選):指定這個 Skill 適用的 Agent 類型。hooks(可選):定義這個 Skill 的生命週期事件。user-invocable(可選):設定這個 Skill 是否可以被使用者直接呼叫。disable-model-invocation(可選):僅允許手動觸發,禁止 AI 主動呼叫。
接下來我將會針對 name 與 description 以外的欄位做說明。
可選欄位(allowed-tools)
簡單來講就是限制這個 Skill 執行時 Claude 只能使用指定的工具,且使用這些工具時不需要詢問使用者許可。
1 | |
可選欄位(model)
你可以指定這個 Skill 適用的模型,而模型你可以透過 Anthropic 提供的 模型清單 來做選擇。
1 | |
可選欄位(context)
將這個 Skill 執行在獨立的 sub-agent 環境,擁有獨立的對話歷史,執行完畢後只回傳結果給主對話,避免中間過程污染主對話的 context。
1 | |
可選欄位(agent)
這個欄位必須搭配 context: fork 一起使用,用來指定這個 Skill 要在哪種 Agent 環境下執行。
Claude Code 內建了三種 Agent 類型:
| Agent 類型 | 用途說明 |
|---|---|
Explore |
適合搜尋檔案、理解架構等任務 |
Plan |
適合設計方案、分析需求等任務 |
general-purpose |
通用型 Agent,適合各種綜合性任務(預設值) |
1 | |
除了內建的 Agent 類型之外,你也可以指定自訂 Agent 的名稱。自訂 Agent 需要放在 .claude/agents/ 資料夾底下:
1 | |
然後在 Skill 中引用:
1 | |
Note
當你使用context: fork時,Skill 會在獨立的 sub-agent 環境中執行,擁有獨立的對話歷史。執行完畢後只會將結果回傳給主對話,避免中間過程污染主對話的 context。這對於需要大量搜尋或分析的任務特別有用。
可選欄位(hooks)
沒錯,你可以替這個 Skill 定義生命週期,例如在載入前或執行後要做什麼事情。
1 | |
而這些 Hooks 都可以在 Hooks 文件 裡面找到詳細的說明。
可選欄位(user-invocable)
這個欄位可以設定這個 Skill 是否可以被使用者直接呼叫,什麼叫做可以直接呼叫呢?也就是你可以透過 / 指令來呼叫這個 Skill。
1 | |
可選欄位(disable-model-invocation)
這個欄位用來禁止 AI 主動呼叫這個 Skill。設為 true 後,這個 Skill 只能透過使用者手動輸入 /skill-name 來觸發,Claude 不會自動判斷並呼叫它。例如:你希望某個 Skill 只在使用者明確要求時才執行,而不是讓 Claude 自動判斷。
1 | |
為了讓你更好理解 user-invocable 和 disable-model-invocation 的差異,這邊整理一個對照表:
| 設定 | 斜線選單 / |
Claude 自動呼叫 | 適用情境 |
|---|---|---|---|
| 預設值 | 可見 | 允許 | 一般用途 |
user-invocable: false |
隱藏 | 允許 | Claude 可用,但不想讓使用者手動呼叫 |
disable-model-invocation: true |
可見 | 禁止 | 使用者可呼叫,但不想讓 Claude 自動判斷 |
字串替換功能
在 SKILL.md 的內容中,你可以使用字串替換來動態插入資訊:
| 變數 | 說明 |
|---|---|
$ARGUMENTS |
呼叫 Skill 時傳入的所有參數 |
${CLAUDE_SESSION_ID} |
當前 Session 的唯一識別碼 |
這個功能在需要記錄或追蹤的場景特別有用:
1 | |
當使用者執行 /session-logger 今天完成了登入功能 時,$ARGUMENTS 會被替換成「今天完成了登入功能」,而 ${CLAUDE_SESSION_ID} 會被替換成當前的 Session ID。
範例 Skills
接下來我們來寫一點點 Skills 的範例,這邊我會示範一個 Code Review 的 Skill,而這個 Skill 擅長 JavaScript 的程式碼審查,為了方便理解,所以 description 我會使用中文撰寫(實際開發上會建議使用英文)。
建立 Skills 方式也很簡單,打開你的專案輸入以下指令:
1 | |
接著把底下貼到 .claude/skills/code-review/SKILL.md 裡面:
1 | |
完成後你的資料夾結構就會長這樣:
1 | |
接著底下這邊是一個不良的 JavaScript 程式碼範例,請你放到專案裡面(如: /bad-code.js ),然後使用 Claude Code 來進行程式碼審查:
1 | |
而這一段程式碼目前有幾個明顯的問題點:
| 類型 | 問題 |
|---|---|
| 命名 | f、d、x、n 完全看不出用途 |
| 安全性 | innerHTML 直接拼接字串 → XSS 風險 |
| 安全性 | eval() 是超級危險的函式 |
| 錯誤處理 | fetch 沒有 try-catch,也沒檢查 response.ok |
| 效能 | 迴圈內重複 getElementById 和修改 DOM |
| 語法 | 使用 var 而非 const/let |
| 比較 | != null && != undefined && != '' 可以簡化 |
接著請你打開 Claude Code(我示範的是 VSCode Plugin),然後在對話框輸入以下 Prompt:
1 | |
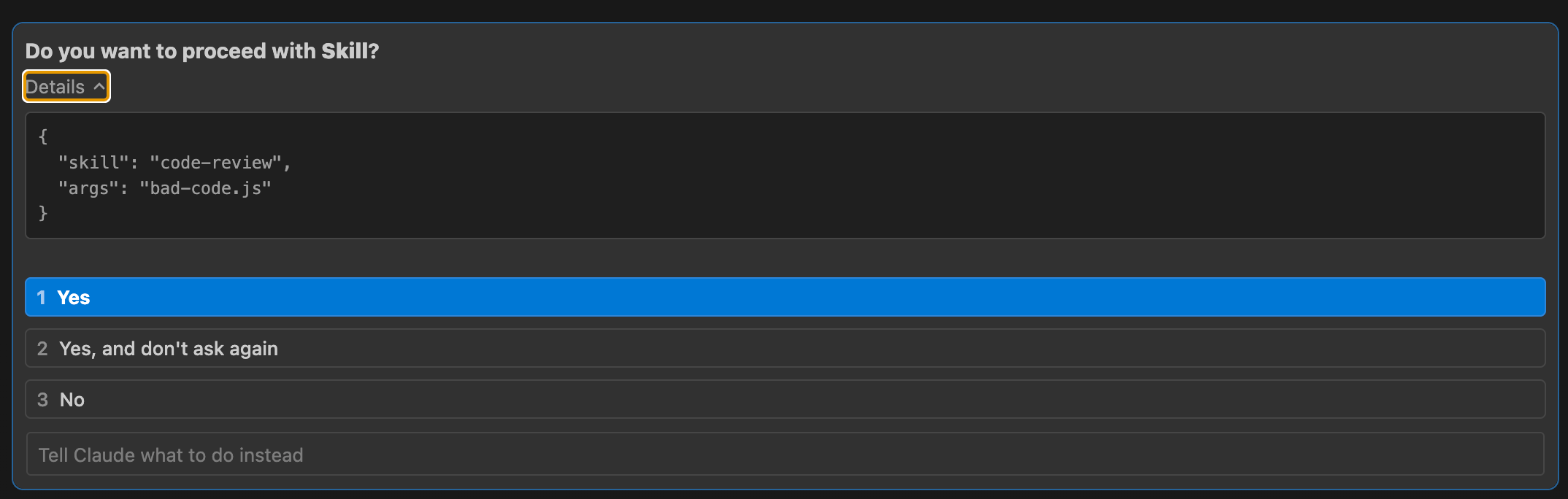
接著你會看到 Claude Code 詢問你 Do you want to proceed with Skill?,按下「Yes」就對了
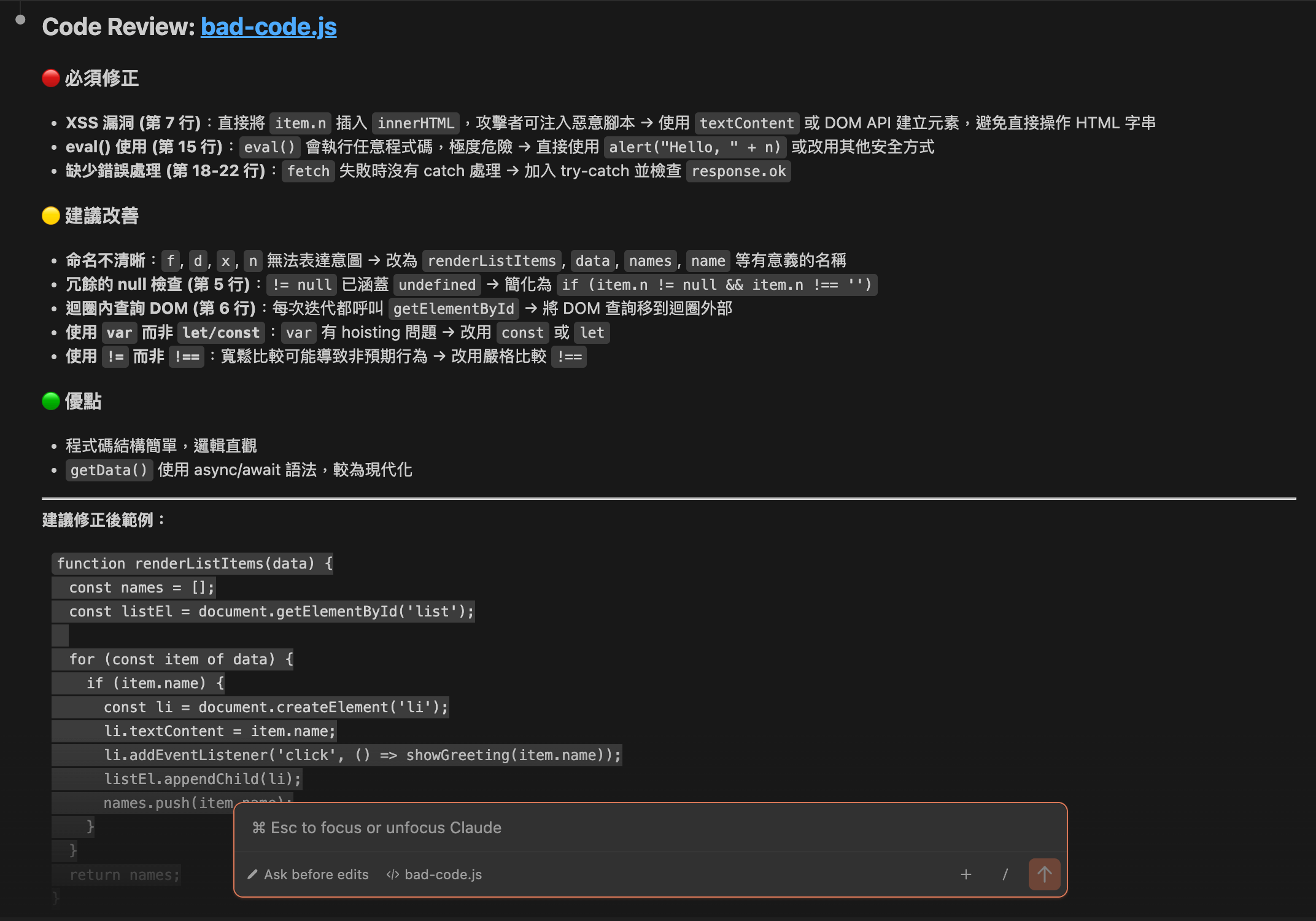
接著你就會看到 Claude Code 使用我們剛剛建立的 code-review Skill 來進行程式碼審查,並且回傳以下結果:
如果你也自己試試看,你也可以下載這個範例專案:GitHub Repository
撰寫最佳實踐
在撰寫 Skills 時,有一些最佳實踐可以讓你的 Skill 更有效率:
SKILL.md 檔案大小
官方建議 SKILL.md 檔案應該保持在 500 行以內,這樣可以確保載入效能。如果你的 Skill 需要大量的參考文件,建議使用外部檔案引用的方式:
1 | |
引用層級
使用單層引用(SKILL.md → reference.md),避免多層巢狀引用(SKILL.md → reference.md → other.md → more.md),這樣可以減少載入時間和複雜程度。
善用腳本
如果你的 Skill 需要執行複雜的邏輯,可以將這些邏輯放在腳本中執行。腳本的執行結果會被傳回給 Claude,但腳本的原始碼不會被載入到 Context 中,這樣可以節省 Token:
1 | |
疑難排解
Skill 沒有被觸發?
最常見的原因是 description 寫得太模糊。一個好的 description 應該要回答以下兩個問題:
- 這個 Skill 做什麼? - 列出具體的功能
- 什麼時候應該使用它? - 包含使用者可能會說的觸發詞
不好的寫法:
1 | |
好的寫法:
1 | |
結語
看到這邊應該滿多人第一直覺就是「這個 Code Review Skill 有必要寫嗎?直接叫 AI 幫我 review 不就好了?」。
這個疑慮是正常的,但是透過 Skills 概念等於你是在打包一個「專業知識」給 AI,就像公司本身都會有屬於自己的技術風格、規範一樣,透過 Skills 你可以把這些「專業知識」打包起來,讓 AI 在執行任務時能夠更符合你的需求。
所以在前面我也是寫了 輸出格式 而非叫 AI 自由發揮,這樣才能確保 AI 回傳的結果是你想要的。
因此把 Skills 想像成一個團隊、一個技能包我認為都是正確的,而這也能夠讓 AI 模型更聚焦於你想要的知識上面,而非被大量的 Raw Data 干擾。
如果我的筆記讓你少踩一個坑、節省 Debug 的時間,
也許你可以請我喝杯咖啡,讓我繼續當個不是 Array 的 Ray ☕
 |
|
 |
|